I created this skill as part of my interview process for a role with Aftersell. My vision for this was to create a tool that could quickly and accurately identify what Aftersell features a brand was not taking advantage of by simply providing Claude with their URL. This is definitely a rough first version, especially given the heavy reliance on browser use. The thought experiment was how much value could we create by trading some amount of quality (i.e. product SME manually find opportunities) in exchange for the scale provided by running multiple audits in parallel.
The skill itself is pretty simple. No API keys or credentials required. It only requires:
- Claude Code
- browser-use installed
python3
It takes a URL and then crawls product page, cart, and checkout. It renders the below output in HTML.
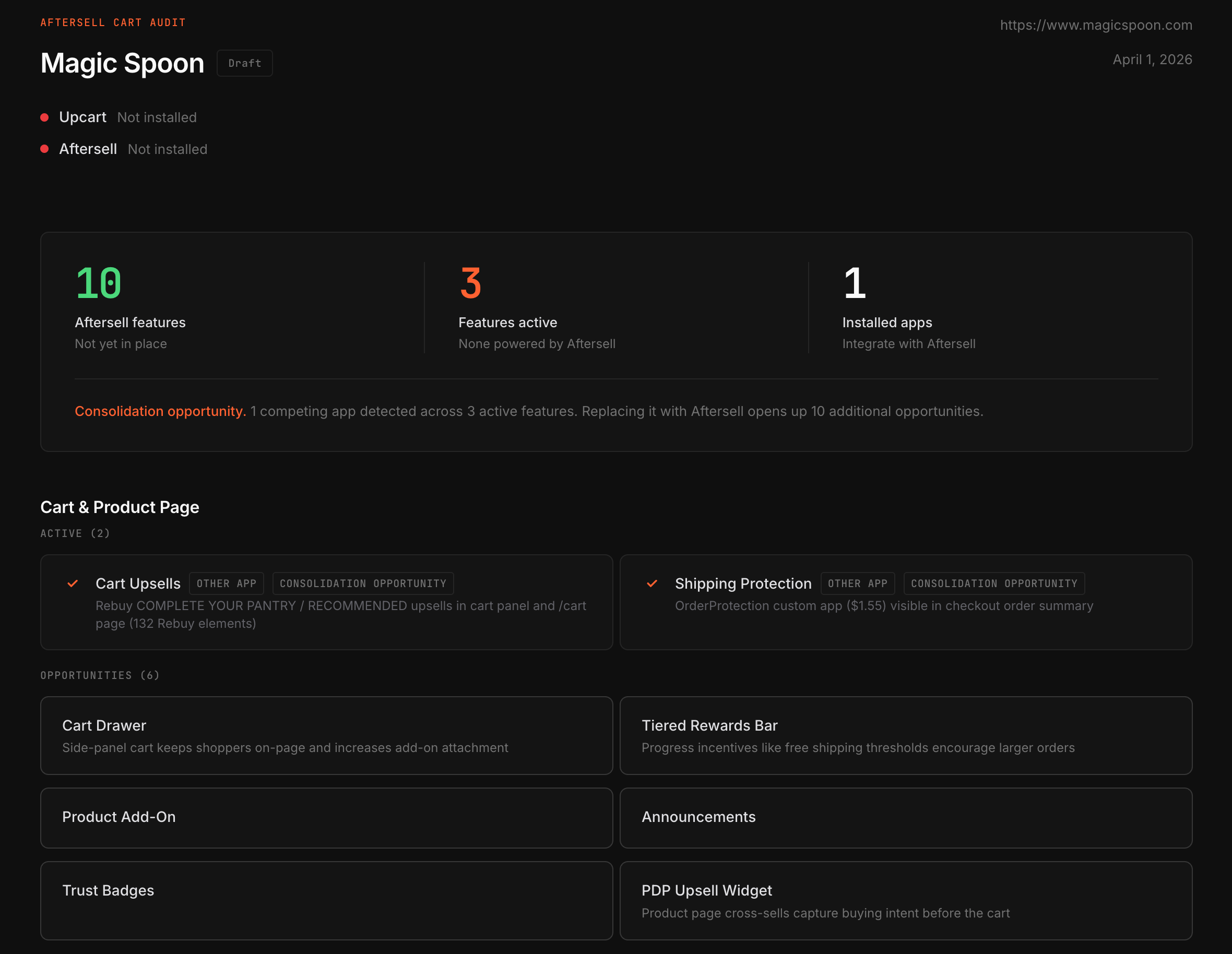
I built this project from a place of what questions do we want answered?
Does this merchant use our apps currently? Is this merchant using a competing app? Do they have any apps installed that Aftersell integrates with?
What needs improvement?
The biggest thing that stands out is this needs evaluation (hence the review before sharing section). The screenshots help to ground this in truth, but lots of room for improvement on accuracy. This would likely mean having to create a golden data set to evaluate the tool against. This is tricky because websites are constantly changing. This youtube from work coming out of Shopify’s ML team talks about a ‘snapshop’ tool they built. Basically it lets the agent train against the version of the site that was in place when annotators built the golden data set. This is far above my pay-grade, but something to strive for.
ROI metrics: I’d like to see the copy within opportunities be more compelling. It’s much more compelling to see “side‑panel cart keeps shoppers on‑page and drives an average order‑value increase of 8–15% by prompting add‑on attachments at the moment they’re most engaged (source)”. Given benchmark and market data in ecommerce isn’t somewhat slow moving, you could do store ongoing to research to pull from, as opposed to to pull fresh, on demand data via API Perplexity.